Today, I want show some data about mtDNA haplogroup U7 because U7 is found in high frequencies in Iranic people including Kurds from Iran. Additionally, I started to use different methods to show how these groups are related to each other.
The current scientific database (Genbank) has 28 fully sequenced U7's, presented here (using CLUSTALW)
The same U7 mtDNA data in a Phylogram:
The same U7 mtDNA data in a Cladogram:
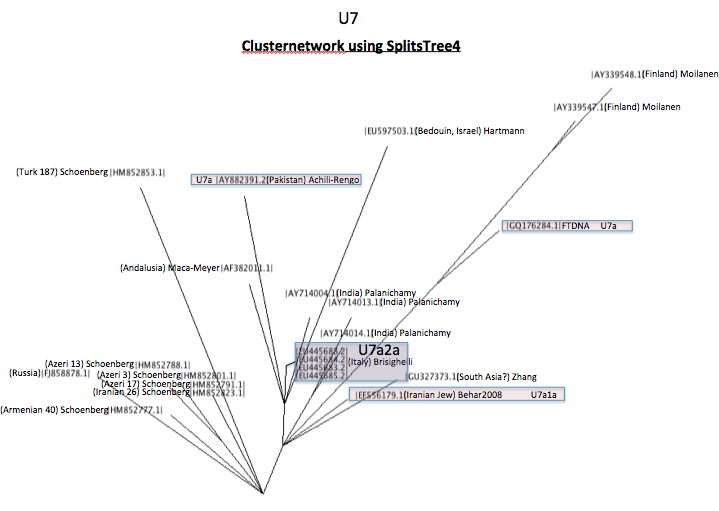
The same U7 mtDNA data in ClusterNetwork:
The same U7 mtDNA data in ConvexHull:
Either way, the mtDNA haplogroup U7 of Kurdish individuals (not fully sequenced) most likely belongs to the same cluster as the Armenian, the Azeris, and the Iranian. The Turkish and Russian individuals somehow belong to this cluster.
Mutations that occur in at least two individuals of this cluster are G143A, T146C, T195C, T310C, T6221C, C12063T, A14047N, A15322G, T16126C, and C16148T. C151T is another typical mutation for this cluster but it is found in the Bedouin, the Iranian Jew, and in samples of South Asia. It almost seems like C151T is the ancestral haplotype and 151C is an old mutation on the early stages of U7.
So, let's see where we can find U7 individuals with these Middle Eastern mutations.
The
FTDNA U7 Haplogroup Project has 69 individuals with mtDNA haplogroup U7
1. G143A was found in one individual from
Turkey (184281). This individual also has the T146C and the
T16126C mutation. This combination was also seen in HM852791(Azeri 17) and HM852823(Iranian 26), however, with an additional T195C mutation, which is lacking in the Turkish individual. FTDNA labeled this individual as U7a4.
2. The individuals
N68725 [Russia, Konakovo (Tver region)] and
130444 [Leah Tatlock 1824-1887 North Carolina] have the T16126C and C16148T, and the T195C mutation. FTDNA labeled these individuals as U7a4 as well.
3. The individual
161466 (Circassian of Northern Caucasus Mtns) has all the private mutations that only occurred in HM852853(Turk187) Schoenberg. They are identical based on the currently tested mutations. FTDNA labeled the individual 161466 as U7a.
4. The individuals
N96539
[
Punjabi (Lahore)], N12921
(India) and N12396
(Nicolosi, Dagata, Italy) have the same T16093C that was described in
AY714004(India), Palanichamy. The same mutation was also seen in the Assyrian 62118
(Jacob) from the
Assyrian Heritage DNA Project.
5. A lot individuals from all over the world seem to have the C151T mutation. This includes the individuals named above and a lot of more:
4049,
130441
(
Hudie Moschel b.c. 1820 Zalipie, Ukraine; U7a),
94738
Tillekeratne (unknown European origin; U7),
223275,
N31946 (Francesca Borg ab. 1872-1940, Malta),
N62232
(need earliest known maternal ancestor info),
189085
(Manglaben Thaker d.1980, India), 138807
(
Unknown),
156252
(need earliest known maternal ancestor info; U7a),
94467
(Cyrla Moskowicz, Poland),
N34983
(Johanna Greenwald, b 1846, Bielefeld, Germany),
158177
(Ukraine),
136319
(Liza Shafran, born Bobryisk, Belarus in 1941),
N44575
(Bella Glezer, Belarus),
59953
(Fredia Elias, b.c.1824, Kepno, Kaliz, Poland)
51408
(Roschen Cohen, Hamburg, Germany, late 1700's)
C151T can be found in the Middle East, South India and Europe.
The
FTDNA Finland DNA project has 3 individuals with mtDNA haplogroup U7
N28814
Finland, Hailuoto
E11886
Margaretha Pehrsdt Koivu, 1671-1766, Haapavesi
75837
Susanna Henrikintytär,1696-1785,Kalajoki,Finland
All three
have the Finnish specific A16166- deletion. The individuals E11886 and
75837 have additional information about HVR2 mutations and both show the
Finnish specific 291.1A mutation, just like the GenBank data of
GQ176284 and AY339548 from Finland. None of them has the U7 Middle Eastern mutations.
The
FTDNA Scottich DNA project has one individual with mtDNA haplogroup U7
| 199889 |
Douglas |
Lettie Jane Ward, 1898-1991 | | |
This individual mtDNA is closest to EU597503 (Bedouin,Israel) with the same mutations (309.1C,
315.1C, C522-, A523- and especially G16129A).